![]()
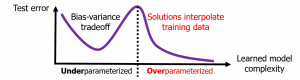
The contemporary practice in deep learning has challenged conventional approaches to machine learning. Specifically, deep neural networks are highly overparameterized models with respect to the number of data examples and are often trained without explicit regularization. Yet they achieve state-of-the-art generalization performance. Understanding the overparameterized regime requires new theory and foundational empirical studies. A prominent recent example is the "double descent" behavior of generalization errors that was discovered empirically in deep learning and then very recently analytically characterized for linear regression and related problems in statistical learning.
The goal of this workshop is to cross-fertilize the wide range of theoretical perspectives that will be required to understand overparameterized models, including the statistical, approximation theoretic, and optimization viewpoints. The workshop concept is the first of its kind in this space and enables researchers to dialog about not only cutting edge theoretical studies of the relevant phenomena but also empirical studies that characterize numerical behaviors in a manner that can inspire new theoretical studies.
Invited speakers:
- Caroline Uhler, MIT
- Francis Bach, École Normale Supérieure
- Lenka Zdeborova, EPFL
- Vidya Muthukumar, Georgia Tech
- Andrea Montanari, Stanford
- Daniel Hsu, Columbia University
- Jeffrey Pennington, Google Research
- Edgar Dobriban, University of Pennsylvania
Organizing committee:
- Yehuda Dar, Rice University
- Mikhail Belkin, UC San Diego
- Gitta Kutyniok, LMU Munich
- Ryan Tibshirani, Carnegie Mellon University
- Richard Baraniuk, Rice University
Workshop dates: April 5-6, 2022
Virtual event
Free registration
Workshop website: https://topml.rice.edu
Abstract submission deadline: February 17, 2022
Call for Contributions available at https://topml.rice.edu/call-for-contributions-2022/