CJ Barberan defended his PhD thesis entitled "NeuroView: Explainable Deep Network Decision Making". CJ's next step is the Microsoft AI Development Acceleration Program (MAIDAP) in Cambridge, MA.
CJ Barberan defended his PhD thesis entitled "NeuroView: Explainable Deep Network Decision Making". CJ's next step is the Microsoft AI Development Acceleration Program (MAIDAP) in Cambridge, MA.
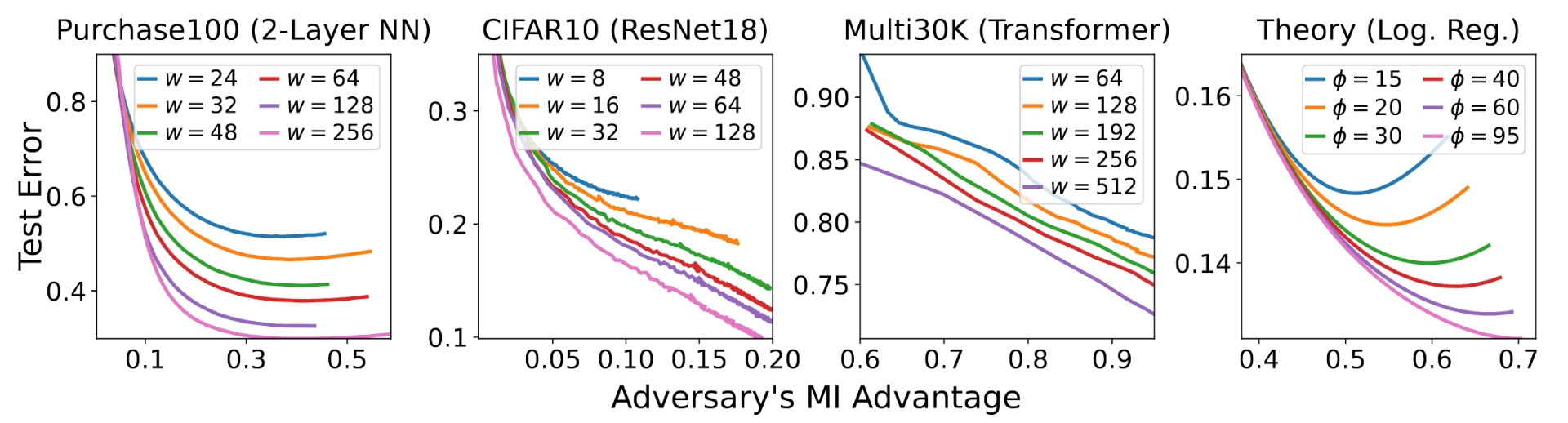
Jasper Tan, Daniel LeJeune, Blake Mason, Hamid Javadi, Richard G. Baraniuk, "Benign Overparameterization in Membership Inference with Early Stopping", arXiv:2205.14055.
Does a neural network's privacy have to be at odds with its accuracy? In this work, we study the effects the number of training epochs and parameters have on a neural network's vulnerability to membership inference (MI) attacks, which aim to extract potentially private information about the training data. We first demonstrate how the number of training epochs and parameters individually induce a privacy-utility trade-off: more of either improves generalization performance at the expense of lower privacy. However, remarkably, we also show that jointly tuning both can eliminate this privacy-utility trade-off. Specifically, with careful tuning of the number of training epochs, more overparameterization can increase model privacy for fixed generalization error. To better understand these phenomena theoretically, we develop a powerful new leave-one-out analysis tool to study the asymptotic behavior of linear classifiers and apply it to characterize the sample-specific loss threshold MI attack in high-dimensional logistic regression. For practitioners, we introduce a low-overhead procedure to estimate MI risk and tune the number of training epochs to guard against MI attacks.

Rice DSP PhD AmirAli Aghazadeh (PhD, 2017) has accepted an assistant professor position at Georgia Tech in the Department of Electrical and Computer Engineering. He has spent the past few years as a postdoc at Stanford University and UC-Berkeley. AmirAli joins DSP PhD alums James McClellan, Douglas Williams, Justin Romberg, Christopher Rozell, Mark Davenport, and Eva Dyer and ECE PhD alum Robert Butera.
 DSP PhD and postdoc alum Christopher Rozell has been named the Julian T. Hightower Chair at Georgia Tech. Chris has had a storied career so far. For his research, he has received the NSF CAREER Award and Sigma Xi Young Faculty Research Award and been named one of six international recipients of the James S. McDonnell Foundation 21st Century Science Initiative Scholar Award. For his teaching, he has received the Class of 1940 W. Howard Ector Outstanding Teacher Award and the CTL/BP America Junior Faculty Teaching Excellence Award. Previously, Chris held the Demetrius T. Paris Junior Professorship. Chris's research interests lie at the intersection of computational neuroscience and signal processing and aim to understand how neural systems organize and process sensory information.
DSP PhD and postdoc alum Christopher Rozell has been named the Julian T. Hightower Chair at Georgia Tech. Chris has had a storied career so far. For his research, he has received the NSF CAREER Award and Sigma Xi Young Faculty Research Award and been named one of six international recipients of the James S. McDonnell Foundation 21st Century Science Initiative Scholar Award. For his teaching, he has received the Class of 1940 W. Howard Ector Outstanding Teacher Award and the CTL/BP America Junior Faculty Teaching Excellence Award. Previously, Chris held the Demetrius T. Paris Junior Professorship. Chris's research interests lie at the intersection of computational neuroscience and signal processing and aim to understand how neural systems organize and process sensory information.
Richard Baraniuk has been elected to the National Academy of Engineering in recognition of his contributions to engineering "for the development and broad dissemination of open educational resources and for foundational contributions to compressive sensing." Election to the National Academy of Engineering is among the highest professional distinctions accorded to an engineer. More from Rice News.
 Richard Baraniuk will present the 2023 AMS Josiah Willard Gibbs Lecture at the Joint Mathematics Meeting in Boston, Massachusetts in January 2023. The first AMS Josiah Willard Gibbs Lecture was given in 1923. This public lecture is one of the signature events in the Society’s calendar. Previous speakers have included Albert Einstein, Vannevar Bush, John von Neumann, Norbert Wiener, Kurt Gödel, Hermann Weyl, Eugene Wigner, Donald Knuth, Herb Simon, David Mumford, Ingrid Daubechies, and Claude Shannon.
Richard Baraniuk will present the 2023 AMS Josiah Willard Gibbs Lecture at the Joint Mathematics Meeting in Boston, Massachusetts in January 2023. The first AMS Josiah Willard Gibbs Lecture was given in 1923. This public lecture is one of the signature events in the Society’s calendar. Previous speakers have included Albert Einstein, Vannevar Bush, John von Neumann, Norbert Wiener, Kurt Gödel, Hermann Weyl, Eugene Wigner, Donald Knuth, Herb Simon, David Mumford, Ingrid Daubechies, and Claude Shannon.

Congratulations to Rice DSP PhD students Jack Wang and Lucy Liu and Rice DSP PhD alum Andrew Lan (now an assistant professor of computer science at UMass-Amherst) on winning the Department of Education IES/NCES Automated Scoring Challenge!
![]()
Richard G. Baraniuk, the C. Sidney Burrus Professor of Electrical and Computer Engineering (ECE) and founding director of OpenStax, Rice’s educational technology initiative, has received the Harold W. McGraw, Jr. Prize in Education. The award is given annually by the Harold W. McGraw, Jr. Family Foundation and the University of Pennsylvania Graduate School of Education and goes to “outstanding individuals whose accomplishments are making a difference in the lives of students.” Baraniuk is one of the founders of the Open Education movement that promotes the use of free and open-source-licensed Open Educational Resources. He is founder and director of OpenStax (formerly Connexions), a non-profit educational and scholarly publishing project he founded in 1999 to bring textbooks and other learning materials into the digital age.
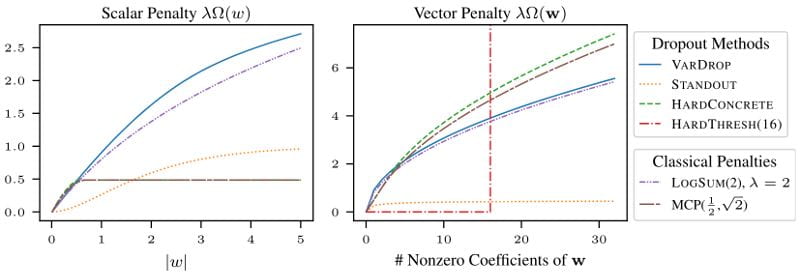
D. LeJeune, H. Javadi, R. G. Baraniuk, "The flip side of the reweighted coin: Duality of adaptive dropout and regularization," NeurIPS 2021, arXiv:2106.0776.
Among the most successful methods for sparsifying deep (neural) networks are those that adaptively mask the network weights throughout training. By examining this masking, or dropout, in the linear case, we uncover a duality between such adaptive methods and regularization through the so-called "η-trick" that casts both as iteratively reweighted optimizations. We show that any dropout strategy that adapts to the weights in a monotonic way corresponds to an effective subquadratic regularization penalty, and therefore leads to sparse solutions. We obtain the effective penalties for several popular sparsification strategies, which are remarkably similar to classical penalties commonly used in sparse optimization. Considering variational dropout as a case study, we demonstrate similar empirical behavior between the adaptive dropout method and classical methods on the task of deep network sparsification, validating our theory.