![]() A. Aghazadeh, A. Lan, A. Shrivastava, R. G. Baraniuk, "RHash: Robust Hashing via L_infinity-norm Distortion," Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), main track, pp. 1386-1394. https://doi.org/10.24963/ijcai.2017/192
A. Aghazadeh, A. Lan, A. Shrivastava, R. G. Baraniuk, "RHash: Robust Hashing via L_infinity-norm Distortion," Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), main track, pp. 1386-1394. https://doi.org/10.24963/ijcai.2017/192
Hashing is an important tool in large-scale machine learning. Unfortunately, current data-dependent hashing algorithms are not robust to small perturbations of the data points, which degrades the performance of nearest neighbor (NN) search. The culprit is the minimization of the L_2-norm, average distortion among pairs of points to find the hash function. Inspired by recent progress in robust optimization, we develop a novel hashing algorithm, dubbed RHash, that instead minimizes the L_1-norm, worst-case distortion among pairs of points. We develop practical and efficient implementations of RHash that couple the alternating direction method of multipliers (ADMM) framework with column generation to scale well to large datasets. A range of experimental evaluations demonstrate the superiority of RHash over ten state-of-the-art binary hashing schemes. In particular, we show that RHash achieves the same retrieval performance as the state-of-the-art algorithms in terms of average precision while using up to 60% fewer bits.
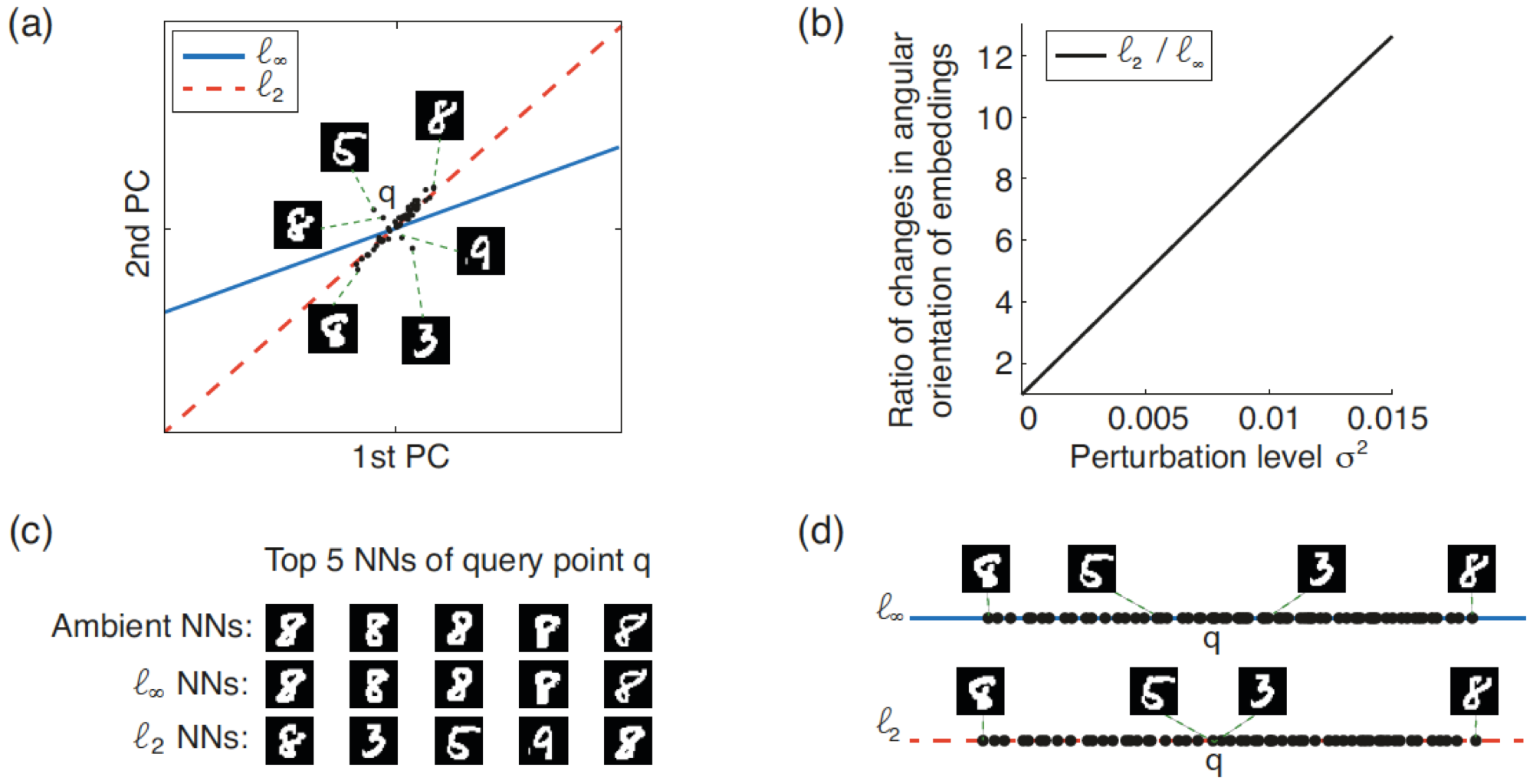
Above is a comparison of the robustness and nearest neighbor (NN) preservation performance of embeddings based on minimizing the L_2- norm (average distortion) vs. the L_1-norm (worst-case distortion) on a subset of the MNIST handwritten digit dataset projected onto its first two principal components. The subset consists of the 50 nearest neighbors (NN) (in the 2-dimensional ambient space) of the centroid q of the cluster of “8” digits. (a) Optimal embeddings for both distortion measures computed using a grid search over the orientation of the line representing the embedding. (b) Robustness of the embedding orientations to the addition of a small amount of white Gaussian noise to each data point. This plot of the mean square error of the orientation of the L_2-optimal embedding divided by the mean square error of the orientation of the L_1-optimal embedding indicates that the latter embedding is significantly more robust to perturbations in the data points. (c) Comparison of the top-5 NNs of the query point q obtained in the ambient space using the L_1- and L_2-optimal embeddings (no added noise). (d) Projections of the data points onto the L_1- and L_2-optimal embeddings (no added noise).